I have been curious about the way search engines crawl the internet. Recently, I revisited materials on this topic covered in my Intro to CS course at McGill. With the spirit of learn by doing, I went to get my hand dirty and made a lightweight search engine that crawls a certain website. You can check it out here.
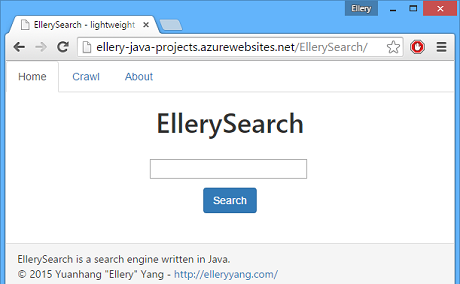
Some basic information on this search engine: it runs on JRE 7 and Tomcat 7; it is configured to search only within a certain domain; it supports only one-word searching; no database backs it up at this moment. By default, it is configured to crawl links within elleryyang.com, so if you want to find out in which posts did I talk about Azure, simply type computer in the search box, and click search.
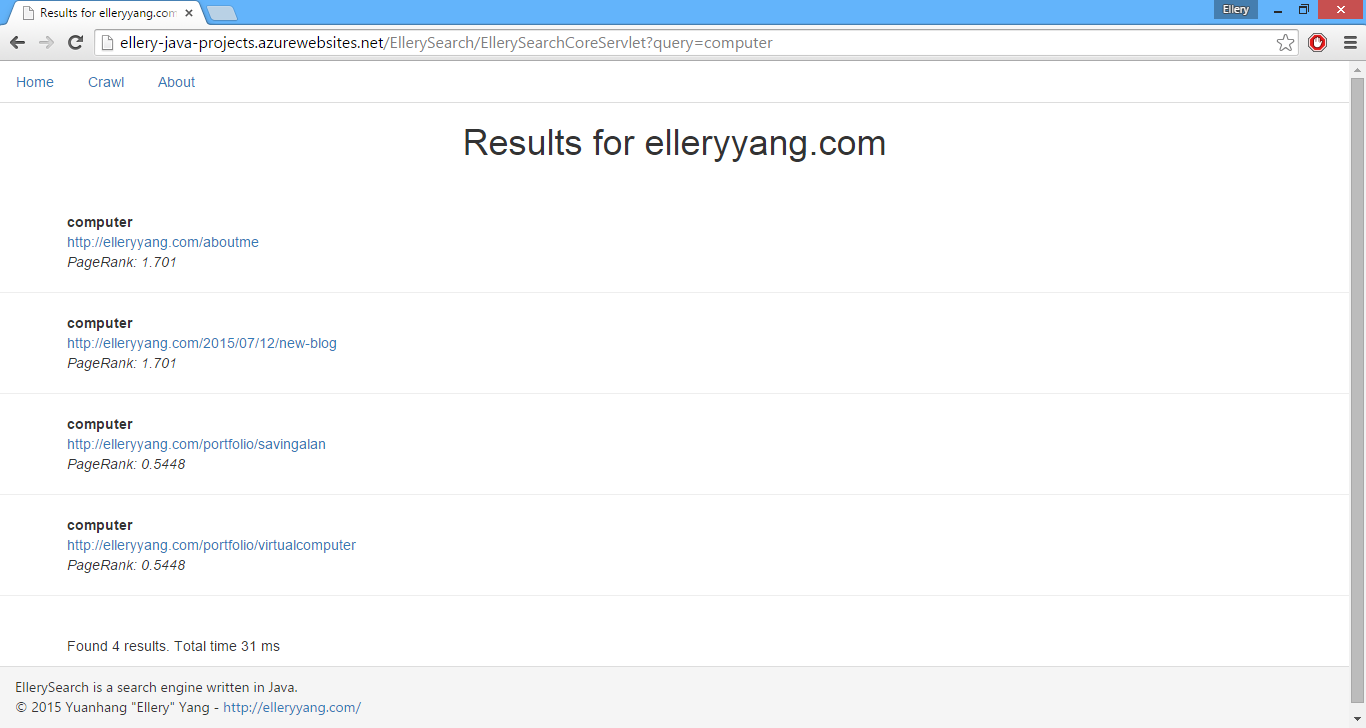
The results page will list all the results in order of PageRank. Each result entry contains a keyword, a link and a PageRank value for user’s reference. Results are restrained in domain elleryyang.com: external links such as my LinkedIn will not be crawled even though they are indeed detected by my spider.
In order to configure the spider to crawl a different site, I go to crawl-reset.jsp and put a new site and a starting point, as well as my admin key in there. If you would like to test the spider, feel free to request an admin key. Here I will crawl my McGill SOCS homepage.

The spider will now crawl all links within domain cs.mcgill.ca/~yyang121 from cs.mcgill.ca/~yyang121. If the crawl is successful, the search engine will be updated to search in cs.mcgill.ca/~yyang121 domain, and I will get a successful message.
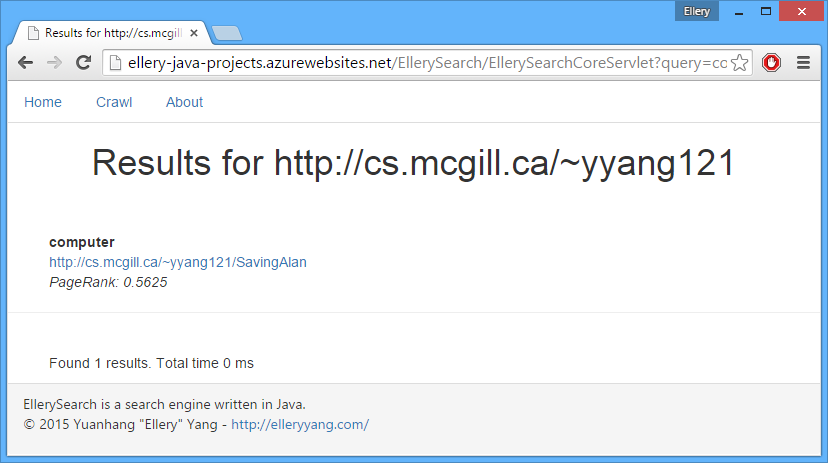
Now if I do a query on some keyword, the result links will be from cs.mcgill.ca/~yyang121.
This project still needs extra work, but feel free to try it out and give feedback!