I have been spending the past week and half working on my new project, Dr.Spider. This is a Java web application used to detect invalid links in a website. Here is a live demo.
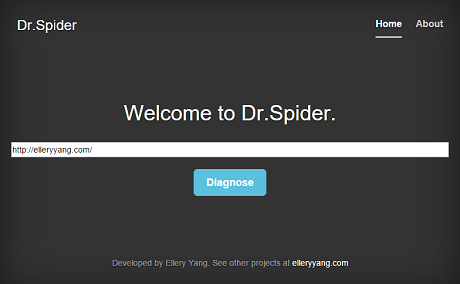
Dr.Spider crawls the web link a user supplies, and performs a Depth-First Search starting from that point. It can detect invalid links in the website, and will display a report if any invalid link is found.
Notice that this is a proof-of-concept project, so it is only configured to crawl links within the given domain name. For example, if I have a link on my home page pointing to a LinkedIn page (which can lead to thousands of links recursively), it will detect this link but ignore it.
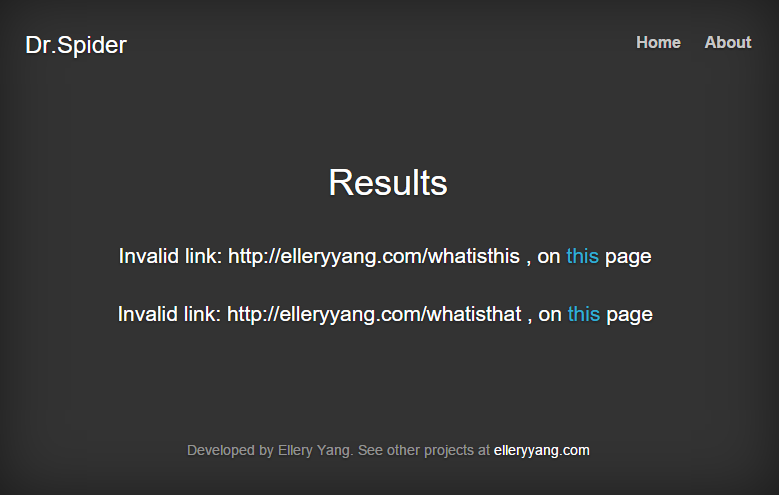
An example: if I put two invalid links in my website, then use Dr.Spider to diagnose it, the result will look like this:
Have fun playing with Dr.Spider!